
Technology: Python, TensorFlow, Django Tags: CNN, Machine Learning, Computer Vision, Deep Learning Image Credits: Jerry Kiesewetter on Unsplash
Digits Classifier
In this project we're training a convolutional neural network to recognize handwritten digits from scratch. Instead of using data that has been made available by other researchers, we'll be using our own hand drawings. With as little as 1010 hand-drawn images the model is able to classify new unseen images with an accuracy of over 96%. The final model can be tried out here.
Classification of digits from 0 to 9 is a text-book example of neural networks. The task provides a few interesting challenges and potential tweaks making it perfect to let your first neural net run wild. While the final deployment is not scope of the summary, this project foreshadows how to build and train a neural net that's responsive to new inputs with a newly created dataset.
For more detail on the process please head over to this jupyter notebook. The dataset can be found here
Data Set
Rather than leaning on one of the available datasets for digit classification, I wanted to introduce new data to the problem. For this purposes I handcrafted over 1000 images drawing digits using the drawing board you can see on the website. Here are three example images of those digits.

To feed those images in the model they are transformed into numpy arrays. Every image contains 4 channels and 256 x 256 pixels per channel. While the first 3 channels contain color information, the fourth dimension stores opacity values. Since this dataset deals with strictly black and white images, the alpha channel contains enough information to move forward. To speed up computation, the images are downsized to 28 x 28 pixels.
Custom Estimators
Instead of using one of TensorFlow's pre-made Estimators such as DNNClassifier I'll be using a custom Estimator that enables us to fine-tune some of the behavior of the final mode.
Model Architecture
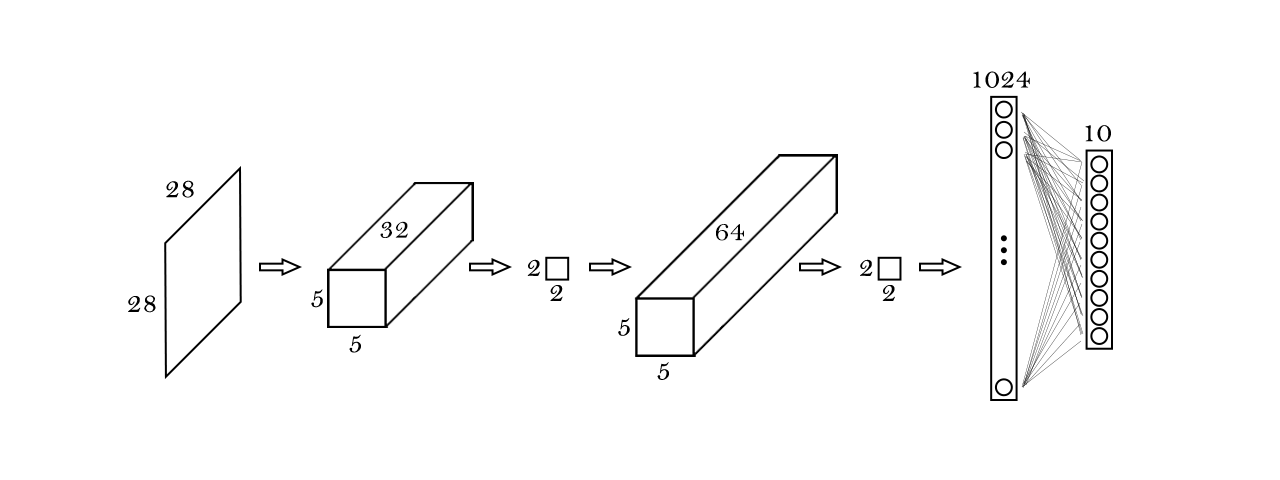
The base model consists out of two convolutional layers with a kernel size 5 x 5 each. The first layer has 32 and the second layer 64 filters. Both apply same padding and are activated through a ReLu function. After each convolutional layer max pooling is performed with a window size of 2 x 2 and a stride of 2. After the second pooling step the multidimensional tensor is being flattened and fed through a fully connected layer with 1024 neurons. This layer feeds into a fully connected layer with 10 units which determines the probability of the image being a certain class through softmax.
The training accuracy of this net was over 95 %. A look on the dev-set performance showed an accuracy score of 45 %. While this result is way better than random guessing it also means the model overfits to a high degree. To help the model generalize better to new data, a dropout step between the first dense and the final layer is introduced. Adding dropout lowered the accuracy on the training set, reducing the overfitting as expected but not improving the dev accuracy significantly. To further improve the network additional data was needed.
Augmentation
To help prove the point that training a neural network with limited data to deliver decent results is possible (and to spare me from further pain in my drawing hand) data augmentation comes to the rescue. When working with any type of data, the amount of training data can be increased by altering the already collected data. Through slight rotations of the original images to varying degrees, as well as zooming-out and shifting the data set was increased to over 60,000 images. In addition normalization was used, to help the model converge quicker. With those tweaks the model scored over 97% accuracy on the dev set.
Results
To validate the performance of the model, we test the final configuration on the test set. To make sure the target class is equally distributed in all used sets, stratification has been applied while splitting. The final model has an accuracy of 96.53% on the data set. This is remarkable, given that only 1010 images are available and shows the potential of neural networks and data augmentation to work together.
If you want to take the model for a spin and add your own drawings to the pile of digits, head over here.